
Are you unsure what personal data your QR codes actually expose – and what you can do about it? Every scan passes through tracking servers that log IP addresses, device types, timestamps, and location data, often without users realizing it. This guide explains five proven anonymization methods that reduce privacy risk while keeping your analytics useful.
What QR Code Scanning Actually Exposes
Before choosing an anonymization strategy, it helps to understand what data is collected in the first place.
When someone scans a código QR dinámico, their request first passes through the platform’s redirect server before landing on your destination URL. That redirect moment is when scan data is logged. Depending on the platform and configuration, this can include:
- IP address (used to approximate geographic location)
- Device type, operating system, and browser
- Timestamp of the scan
- Scan count (total and unique)
The destination website can collect even more – cookies, referrer data, and any information users enter. Códigos QR estáticos bypass this redirect entirely and forward users directly to the final URL without logging anything, but they also offer no analytics.
Understanding these data flows is the starting point for applying the right anonymization method. You can also review qué datos recopilan los códigos QR dinámicos for a deeper breakdown before deciding on an approach.
See Exactly What Your QR Codes Track Utilice el de Pageloot panel de análisis integrado to review what scan data is collected and configure your tracking to match your privacy requirements.
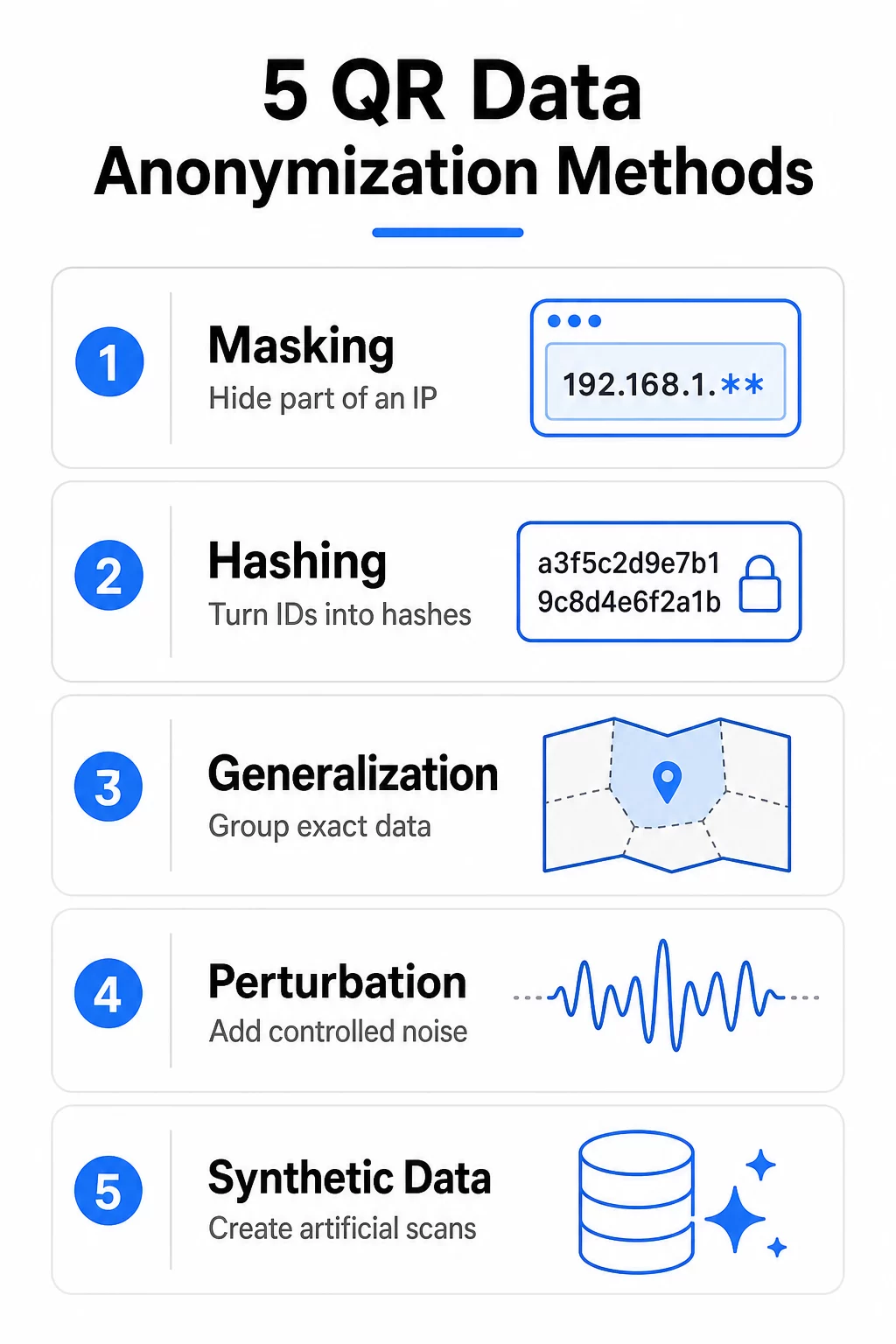
5 Methods to Anonymize QR Code Data
1. Masking
Masking obscures or substitutes sensitive data fields so that the underlying values cannot be read, while the data itself remains structurally usable. In a QR code context, this typically applies to data collected at the redirect server or stored in analytics systems – for example, replacing the last octet of an IP address with a zero before it is written to a database.
Privacy strength: Masking offers moderate protection. It prevents casual exposure but remains vulnerable to inference attacks if enough context is available. It is best used as one layer in a broader privacy strategy rather than a standalone solution.
Data utility: Because masking preserves the structure of the data, aggregate analysis remains fully functional. You can still measure scan volume, regional trends, and device distribution without accessing individual identities.
Implementation complexity: Masking is among the easiest techniques to deploy. It involves identifying which fields need protection and applying substitution rules consistently. Modern QR code platforms can apply IP masking automatically at the point of collection, before any value is stored.
Regulatory compliance: Masking alone does not satisfy GDPR anonymization requirements, because regulators treat masked data as still potentially linkable to individuals. It does, however, support compliance by reducing exposure and demonstrating good-faith data minimization – one of the core principles under both GDPR and CCPA.
2. Hashing
Hashing converts sensitive values into fixed-length strings using a cryptographic algorithm, making it impossible to recover the original input from the output. A user’s email address or device identifier, for example, becomes a scrambled string that can still be used for matching or deduplication within a system.
Privacy strength: Strong in principle, but not absolute. Low-entropy values – those with a limited set of possible inputs – can be vulnerable to brute-force attacks. Adding a salt (a random string appended before hashing) and rotating keys regularly makes attacks significantly harder.
Data utility: Hashing is well-suited for deduplication and consistency checks, such as identifying repeat scanners without storing their identifiers. It is less useful for detailed behavioral analytics or integrations that require the original values.
Implementation complexity: Basic hashing is straightforward and widely supported in most development environments. The additional steps of salting and key management add complexity and require a secure system for storing and rotating those values.
Regulatory compliance: The Federal Trade Commission has stated that hashing alone does not constitute anonymization. The Article 29 Working Party (now the European Data Protection Board) has similarly noted that “hashing is a useful security measure, but is not a method of anonymisation.” Under GDPR, hashed personal data is still treated as personal data. Under CCPA, hashed data may qualify as deidentified if appropriate technical controls and internal policies are in place, but businesses must enforce those policies consistently and document their risk assessments.
3. Generalization
Generalization replaces specific data values with broader categories or ranges. Instead of storing a precise timestamp, you store the hour or day. Instead of storing a city, you store a region. Instead of an exact age, you store an age band.
For QR code analytics, this might mean recording that a scan occurred “in the afternoon on a weekday” rather than at 2:17 PM on a Tuesday, or attributing a scan to “Pacific Northwest” rather than a specific ZIP code.
Privacy strength: Moderate, and dependent on how broadly values are grouped. The risk of re-identification grows when multiple generalized fields are combined. A 2007 case involving a Netflix dataset showed that researchers could re-identify users by cross-referencing generalized ratings data with external sources – a warning that even aggregated data needs careful design.
Data utility: Generalization preserves enough detail for trend analysis and campaign measurement. Businesses using QR codes in retail or hospitality can still identify peak periods, popular regions, and device preferences without exposing individual behavior.
Implementation complexity: Generalization can be implemented manually by setting category boundaries, or automatically using algorithms that balance privacy and data resolution. Either approach requires defining clear policies about what level of detail is appropriate for each data field.
Regulatory compliance: Generalization aligns with the data minimization principles in GDPR and CCPA, which require collecting only what is necessary for a specified purpose. It does not automatically satisfy anonymization standards on its own but contributes meaningfully to a layered approach. Documenting your generalization decisions and reviewing them regularly supports audit readiness.
4. Data Perturbation
Data perturbation introduces small, controlled amounts of noise into numeric or geographic data. Rather than recording an exact value, the system stores a slightly modified version – a timestamp shifted by a few minutes, coordinates rounded to a broader area, or a count adjusted within a defined range.
This approach is common in fields where statistical accuracy matters more than precision for individual records. Hospitals have used it to share patient data with researchers while protecting private medical details; financial institutions apply it to transaction data to prevent exposure of sensitive patterns.
Privacy strength: Perturbation strikes a balance between masking specific details and preserving analytical patterns. The level of privacy it provides depends directly on how much noise is introduced. Too little, and individual records remain identifiable. Too much, and the data loses meaning.
Data utility: Unlike techniques that fully remove original values, perturbation retains the statistical relationships within a dataset. Trend analysis, peak identification, and geographic clustering all remain valid – just without the ability to pinpoint exact individuals.
Implementation complexity: Perturbation requires more technical judgment than masking or generalization. The choice of transformation method – random noise, value swapping, or mathematical transforms such as wavelet or Fourier methods – affects both performance and privacy outcomes. Wavelet transforms, for example, operate at O(n) time complexity, making them faster than some alternatives. Careful calibration is needed to avoid introducing systematic bias.
Regulatory compliance: Perturbation supports GDPR’s data minimization requirements and provides a defensible technical safeguard. It does not guarantee full anonymization but demonstrates a meaningful effort to limit identifiability, which regulators generally view favorably when combined with other controls.
5. Synthetic Data Generation
Synthetic data generation creates entirely artificial datasets that mirror the statistical properties of real data without containing any actual user information. Rather than altering what was collected, it replaces the original data with fabricated records that behave like real ones for analytical purposes.
For QR code analytics, this means generating realistic scan timestamps, plausible geographic distributions, and representative device mixes – without any of those records corresponding to real scans by real people.
Privacy strength: Synthetic data offers the strongest privacy protection of the five methods. Because it contains no real personal information, there is no risk of re-identification even if the dataset is exposed. A breach of a synthetic dataset has no privacy consequences for individuals.
Data utility: When generated well, synthetic data preserves the statistical relationships needed for trend analysis, model training, and feature testing. It also makes it possible to simulate scenarios that are rare in real data – useful for stress-testing analytics systems or training machine learning models on edge cases.
Implementation complexity: This is the most resource-intensive method. Generating high-quality synthetic data requires specialized tools, significant computational resources, and validation processes to confirm the synthetic dataset accurately represents the original. Organizations typically need dedicated expertise or third-party platforms to implement it reliably.
Regulatory compliance: Because synthetic data contains no personal information, it inherently falls outside the scope of GDPR, CCPA, and most other privacy regulations. This makes it particularly valuable for industries with strict compliance requirements, such as healthcare and education. It eliminates the re-identification risk that other methods must actively manage.
Start Collecting Privacy-Friendly QR Analytics De Pageloot Generador de Códigos QR Dinámicos aggregates scan data at the country and city level, groups devices into general categories, and never exposes individual identities in its analytics. Try it free for 14 days.
Method Comparison
| Método | Privacy Strength | Data Utility | Implementation Complexity | Cumplimiento normativo |
|---|---|---|---|---|
| Masking | Moderado | Alta | Baja | Partial – supports minimization, not full anonymization |
| Hashing | Moderate–High | Medio | Medio | Partial – still personal data under GDPR |
| Generalization | Moderado | Medium–High | Low–Medium | Partial – supports minimization principles |
| Data Perturbation | Moderado | Medium–High | Alta | Good – flexible, defensible safeguard |
| Synthetic Data | Muy alta | Alta | Muy alta | Excellent – inherently outside GDPR/CCPA scope |
The right method depends on your use case. Masking and generalization are practical starting points for most QR code analytics platforms. Hashing works well for deduplication tasks where exact values are not needed downstream. Perturbation suits scenarios where statistical accuracy is critical. Synthetic data is the strongest option when compliance risk is high or when you need to share datasets externally.
Many organizations use these methods in combination rather than choosing just one – for example, applying IP masking at collection time, generalizing location data to the city level, and generating synthetic datasets for any external analytics partners.
How Pageloot Approaches QR Code Data Privacy
Pageloot’s analytics are built around aggregate, non-personally identifiable data. Location data appears at the country or city level, device information is grouped into general categories like iOS or Android, and IP addresses are not stored in a form that identifies individuals. The platform provides flexible data retention options, and enterprise users have access to CSV exports that support further anonymization downstream.
For businesses running campaigns across multiple regions, the analytics features allow you to measure performance without building profiles on individual users. Pageloot also supports GDPR-compliant QR code analytics through consent pop-ups, data management tools, and encrypted storage with regular security reviews.
For context on which leyes de privacidad de códigos QR apply to your specific situation – including GDPR, CCPA, HIPAA, and others – and how to implement appropriate data retention rules for QR code analytics, Pageloot’s knowledge base covers each regulation with practical guidance.
Choosing the Right Approach for Your Business
No single anonymization method works for every situation. The FTC’s guidance is clear: collect only what you need, keep it only as long as necessary, and dispose of it properly when it has served its purpose. That principle applies regardless of which technical method you use.
For most businesses using QR codes in marketing or operations, a practical starting point is to enable IP masking and location generalization at the platform level, review what data your analytics integration collects, and set defined retention limits. For organizations in regulated industries or those sharing data with third parties, stronger methods – perturbation or synthetic data – may be worth the additional implementation investment.
The goal is not perfect anonymization at the cost of all insight. It is finding the level of privacy protection appropriate to the sensitivity of the data you collect, the regulations that apply to your business, and the trust you want to build with your users.
Explore Pageloot’s full range of QR code features to see how privacy controls fit into the broader platform, or review riesgos de privacidad de los códigos QR y cómo evitarlos for a broader look at the threat landscape.
Preguntas Frecuentes
No. The Article 29 Working Party has stated that hashing is a security measure, not an anonymization method. Under GDPR, hashed personal data is still classified as personal data and subject to the same protections as the original. To qualify as anonymous under GDPR, data must be irreversibly stripped of any connection to an identifiable individual.
Masking substitutes or obscures specific field values – for example, replacing part of an IP address with zeros – while keeping the structure intact. Generalization replaces precise values with broader categories, such as converting an exact timestamp to a time-of-day range or a city to a region. Masking is better for protecting specific identifiers; generalization is better for reducing the resolution of data across multiple fields simultaneously.
Synthetic data generation provides the strongest compliance posture because it contains no real personal information and falls outside the scope of most privacy regulations. For businesses that need to retain real scan data, a combination of IP masking, location generalization, and defined retention limits provides a defensible baseline. The right method depends on your data sensitivity, how you use the analytics, and whether you share data with third parties.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}